OCR PDF
OCR PDF yra internetinis įrankis, naudojantis Optinio Simbolio Atskyrimu skirtu ištraukti tekstą iš PDF failų, paverčiant juos redaguotinais tekstais. Tai naudinga seniems ar fizinės formos dokumentams paversti paieškai tinkamais, skaitmeniniais failais.
Overview
OCR PDF
OCR PDF yra patogus įrankis, kuris, naudodamasis optinio simbolių atpažinimo technologija, ištraukia tekstą iš PDF failų.
Šis procesas transformuoja tekstų paveikslėlius į redaguojamą tekstą, todėl jis yra puikus įrankis seniems dokumentams ar tekstams iš paveikslėlių skaitmeninti.
Įrankis nuskenauja visą dokumentą, kad atpažintų spausdintą, ranka parašytą ar atspausdintą tekstą, o tada jį atitinkamai konvertuoja.
Dėl to, PDF tampa paieškomas ir indeksuojamas, kas gali būti labai naudinga, jei dirbate su dideliais dokumentais.
Taip pat galite lengvai ištaisyti bet kokias klaidas, kurios gali būti atsiradusios dėl rankraščio apdorojimo.
Kol originalus rankraštis yra aiškus, OCR PDF įrankis gali jį apdoroti su dideliu tikslumu.
OCR PDF konversija labai prisideda prie darbo su dokumentais produktyvumo ir efektyvumo didinimo.
Screenshots
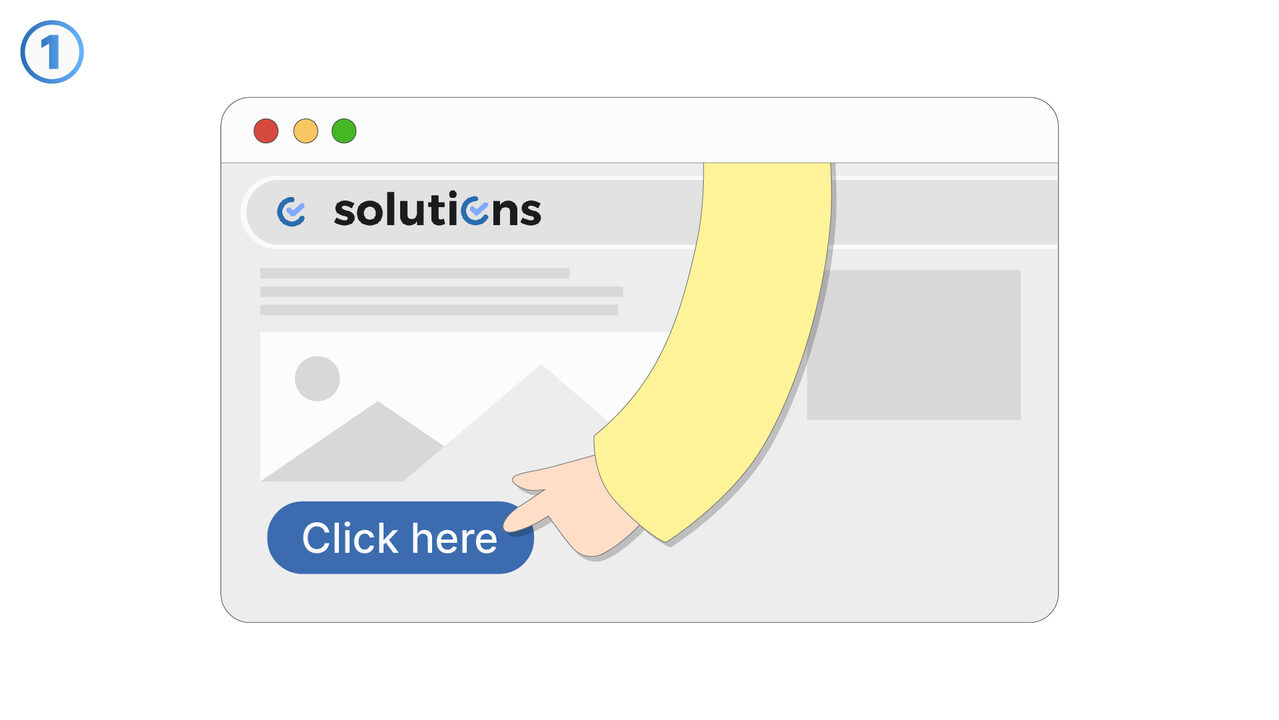
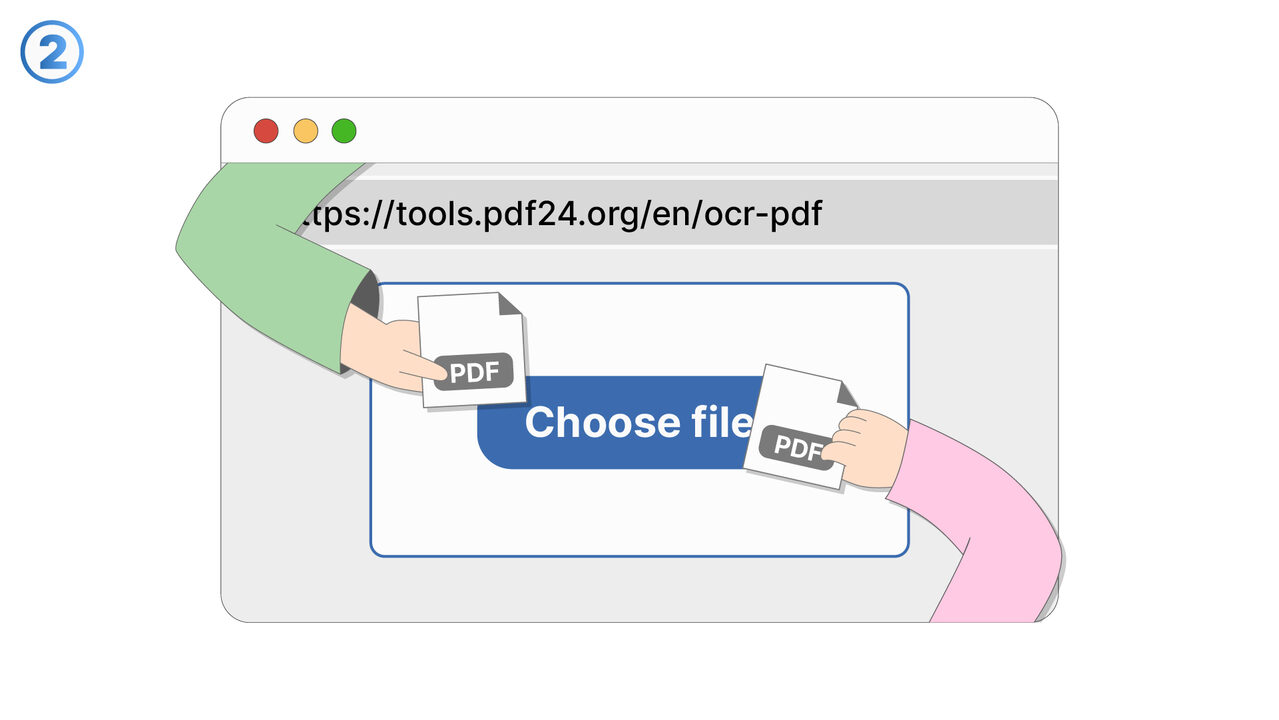
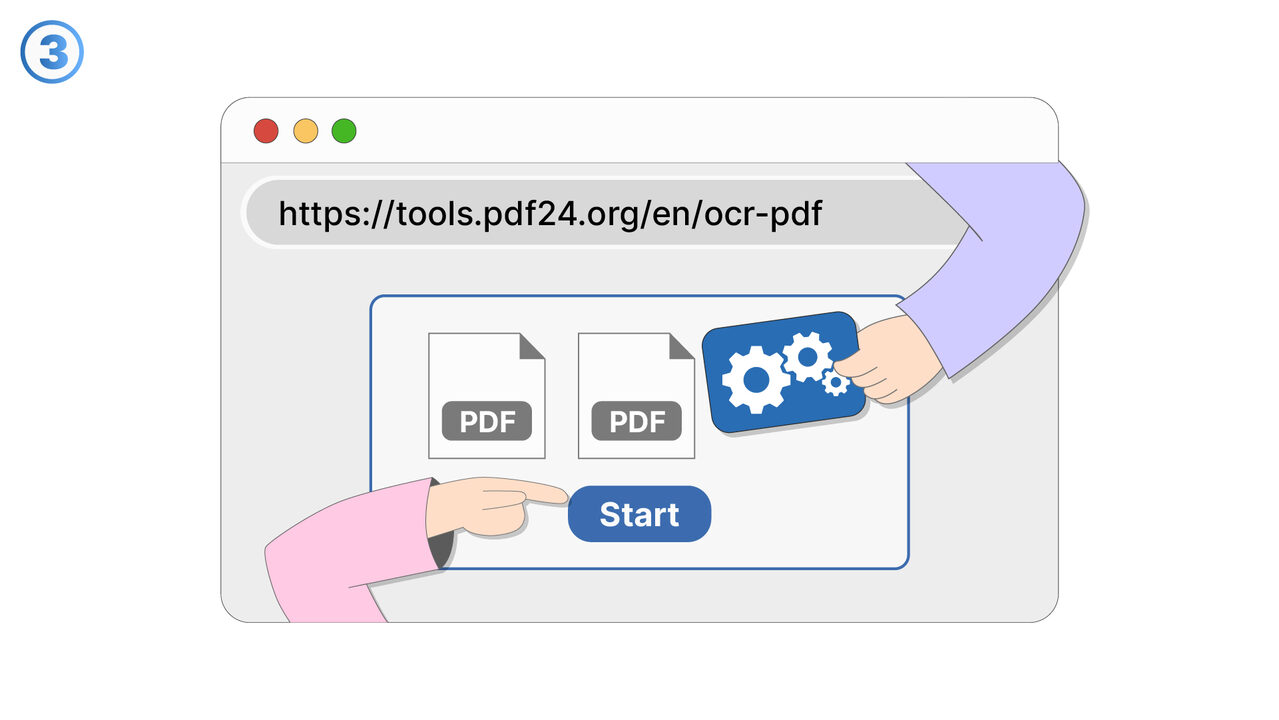
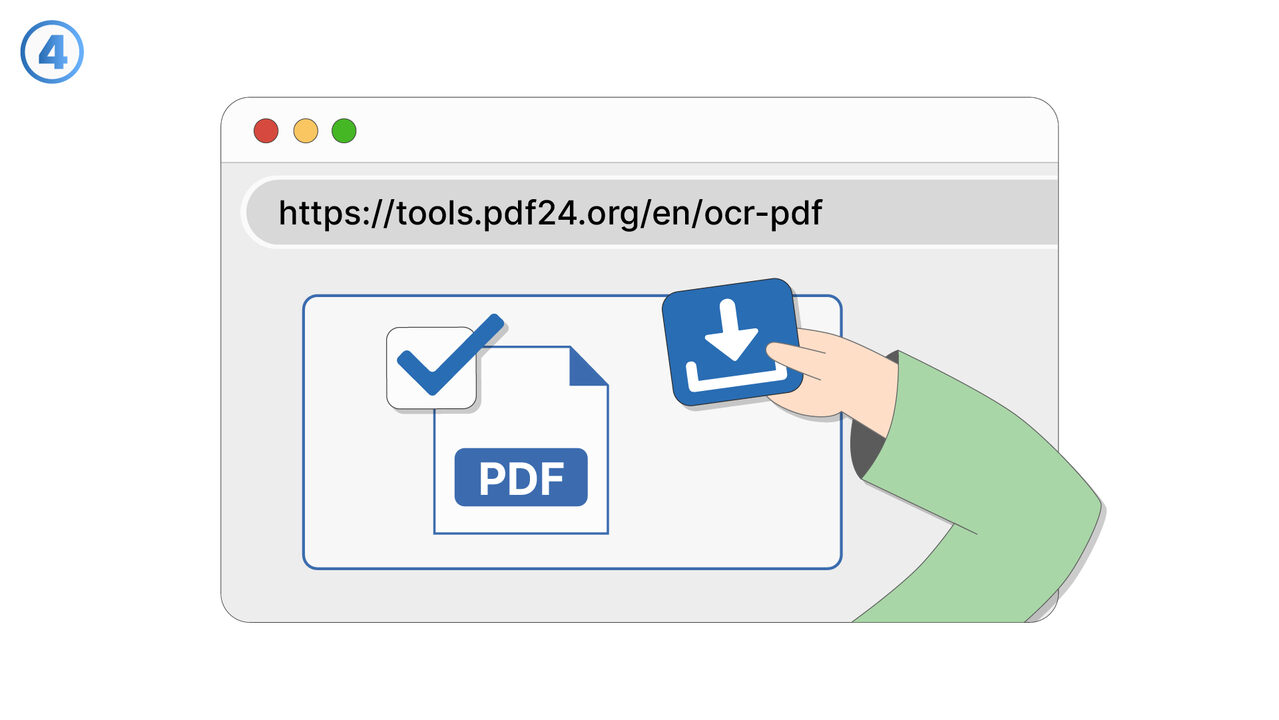
Link To Tool
Find the solution to your problem via the following link.
External Resource
https://tools.pdf24.org/en/ocr-pdf
Opens in a new tab — external site not affiliated with MangoByte
Use this tool as a solution to the following problems
- Aš negaliu redaguoti teksto savo PDF faile ir man reikia sprendimo tam.
- Turiu problemų, bandydamas digitalizuoti senus popierinius dokumentus.
- Aš negaliu paieškoti turinio savo PDF faile ir man reikia įrankio teksto atpažinimui.
- Turiu problemų kopijuodamas tekstą iš nuskanuoto dokumento.
- Turiu problemų ištraukiant ir skaitmeninant tekstą iš fizinės dokumentacijos.
- Aš negaliu ištaisyti klaidų savo nuskaitytuose PDF dokumentuose.
- Turiu problemų ištraukiant ir tvarkant tekstą iš savo fizinės dokumentacijos.
- Man sunku ištraukti tekstą iš fizinių dokumentų ir juos skaitmenizuoti.
- Aš negaliu indeksuoti ir kategorizuoti teksto savo nuskenuotame PDF.
- Man sunku konvertuoti tekstą iš vaizdu pavaizduotuose PDF failuose į redaguojamą tekstą.
Know a better solution? Let us know.
If you know of a tool or approach that could help people solve a problem we haven't covered yet, we'd love to hear about it.