OCR PDF
OCR PDF е онлајн алатка која користи оптичко препознавање на знаци за да извади текст од PDF датотеки и да ги претвори во уредувачки текстови. Таа е корисна за претворање на стари или физички документи во пребарувачки дигитални датотеки.
Overview
OCR PDF
OCR PDF е корисен алат кој користи оптичко препознавање на знаци за извлекување текст од PDF датотеки.
Овој процес ги претвора сликите од текст во уредувачки текст, што го прави идеален алат за дигитализација на стари документи или текстови од слики.
Алатот го скенира целиот документ за да го препознае отпечатениот, рачно напишаниот или отпечатениот текст, а потоа соодветно го конвертира.
Со тоа, PDF станува пребарувачки и индексирувачки, што може да биде доста предност ако работите со големи документи.
Исто така, лесно може да ги исправите сите грешки што може да се појавиле поради обработката на рачните писма.
Додека оригиналното рачно писмо е јасно, OCR PDF алатот може да го обработи со висок степен на прецизност.
Конверзијата на OCR PDF значително придонесува за подобрување на продуктивноста и ефикасноста при работа со документи.
Screenshots
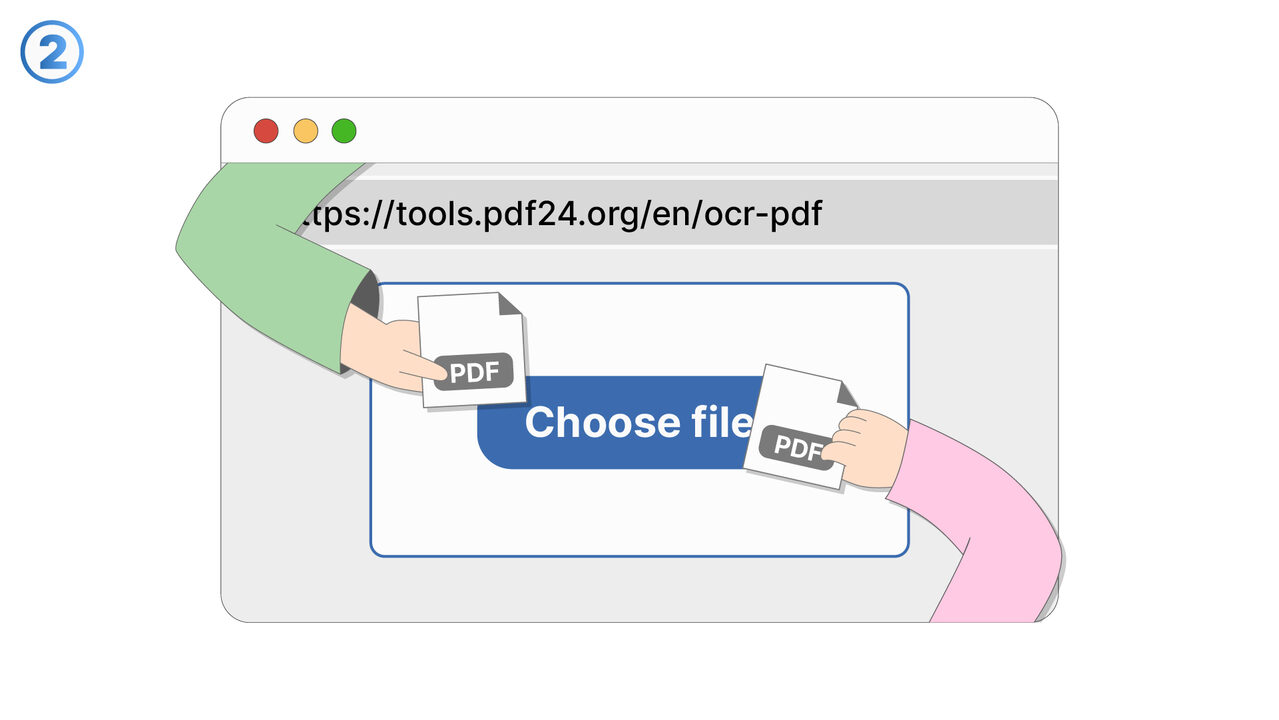
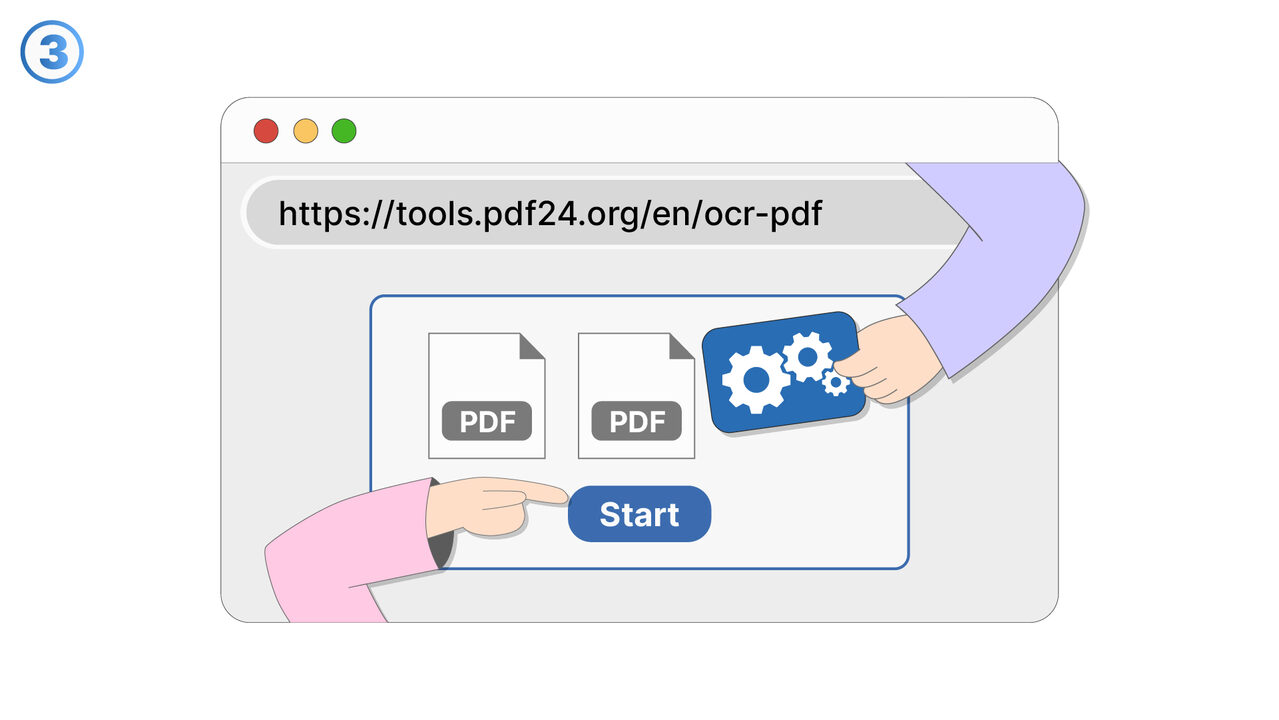
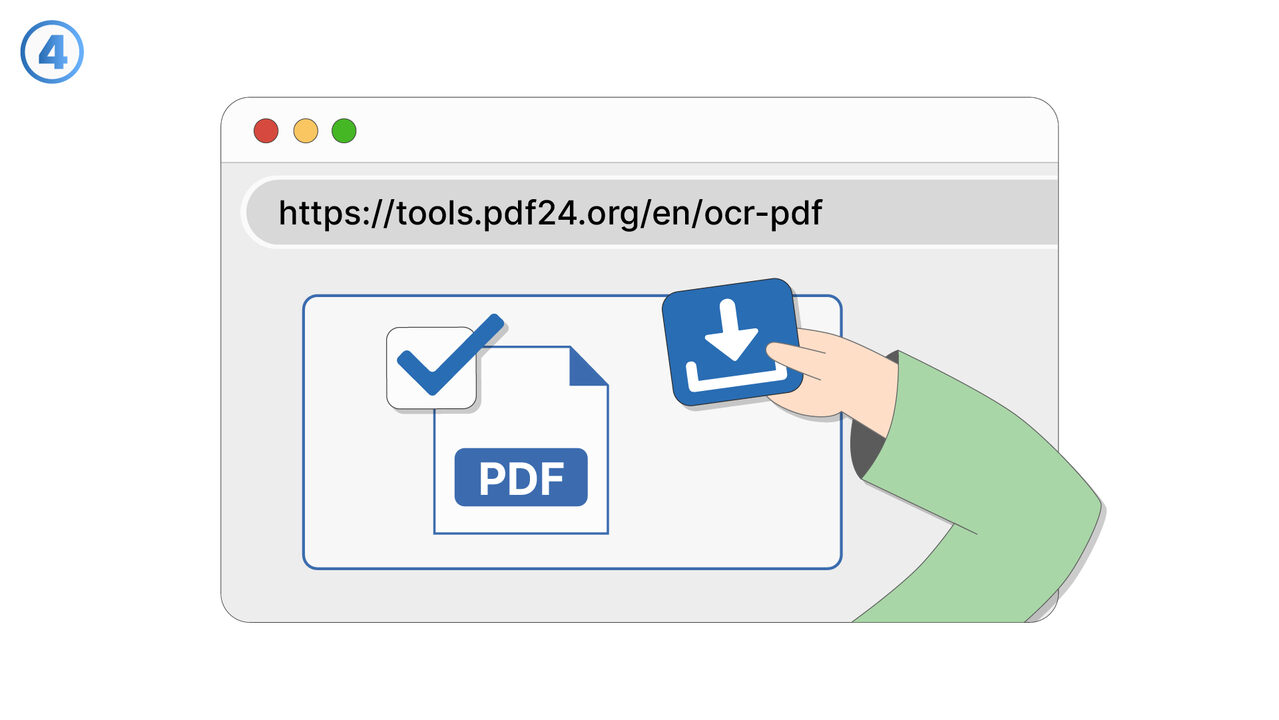
Link To Tool
Find the solution to your problem via the following link.
External Resource
https://tools.pdf24.org/en/ocr-pdf
Opens in a new tab — external site not affiliated with MangoByte
Use this tool as a solution to the following problems
- Не можам да го уредувам текстот во мојата PDF-датотека и ми треба решение за тоа.
- Имам проблеми при дигитализација на стари документи од хартија.
- Не можам да го пребарувам содржината во мојата PDF-датотека и ми треба алатка за препознавање на текст.
- Имам проблеми при копирањето на текст од скениран документ.
- Имам проблеми со екстракција и дигитализација на текст од физички документи.
- Не можам да исправам грешки во моите скенирани PDF-документи.
- Имам проблеми да го извадам текстот од моите физички документи и да го управувам.
- Имам тешкотии да извлечам текст од физички документи и да ги споделувам дигитално.
- Не можам да ги индексирам и категоризирам текстовите во мојата скенирана PDF датотека.
- Имам тешкотии да го претворам текстот од PDF документи прикажани како слики во уредлив текст.
Know a better solution? Let us know.
If you know of a tool or approach that could help people solve a problem we haven't covered yet, we'd love to hear about it.